Windows x86 C++ Calling Conventions Cheat Sheet
Jan 25, 2026
Noodling with reverse engineering Windows applications needs me to know these things but they refuse to stick in my brain, so I have put them in one place.
All stack parameters are passed in right-to-left order.
| Name | Stack cleaned by | Parameters |
|---|---|---|
thiscall |
Callee | this in ECX, params on stack |
fastcall |
Callee | First in ECX, second in EDX, rest on stack |
cdecl |
Caller | Stack |
stdcall |
Callee | Stack |
PortMaster Releases RSS Feed
Jan 4, 2026
I love me an open handheld games console and I love playing games on them which were never intended to be, so I love PortMaster. I don’t like having to do stuff, such as keeping tabs on which games have been ported. So I threw together a little project to scrape the PortMaster releases JSON and generate an RSS feed I (and you) can subscribe to and keep track of releases as they happen. The feed lives here https://ste.vet/portmaster-rss/feed.xml and is updated at 2:22 (🤷) every day.
Ultima IX: Ascension Asset Archaeology
Jan 2, 2026
I found myself looking at screenshots of the early development of Ultima IX. This one in particular caught my eye - seeing these dev tools from the 90s got me wondering if there was any trace of this editor, or this original isometric version of Ultima 9, in the very different game that eventually shipped in 1999.
{kind=link}
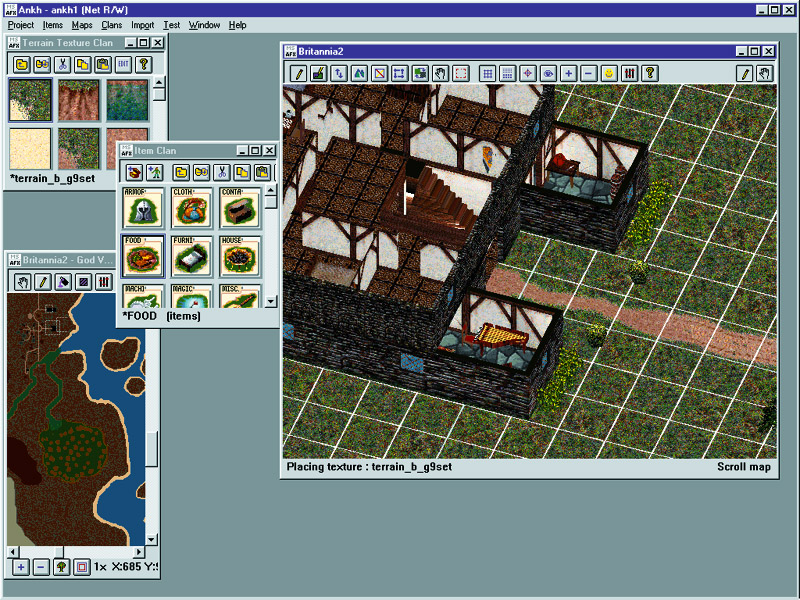
I couldn’t find any modern-Windows-compatible tools for viewing the U9 asset files, but I found some pretty extensive documentation, so I figured I’d just roll my own. You can now find it on Github.
After a lot of scrolling through images, I found these:















































































I didn’t find anything more from the editor in the assets or from poking around in the executable but it’s neat to find traces of the developer tools tucked away in the game files. I did find these terrain tiles, which have a suspiciously similar noisy dithering to the old screenshots, and a green marbley tileset that looks to date back to then:



Compare with:



The final interesting find was this character art, featuring Teenage Mutant Ninja Turtle-esque green, four-armed alien folk wielding swords, spears and what looks to be an actual gun. I would love to know more about this - as far as I can tell it doesn’t feature in the game and it’s not buried alongside other assets that explain it.

If you’re interested in having a poke around these files, you can check out my projecet on Github, or I later found that this person has already dumped the images online. I shall now resume my wait for the digital playground for the new millennium.


UltraHLE Technical Information
Dec 29, 2025
I recently stumbled on this comment on a Reddit post about MVG’s UltraHLE retrospective. They didn’t link to the source they were quoting and no amount of Googling gave me what I was looking for. Many clicks around archive.org eventually gave me the goods. Turns out the comment containted all the text from the page, but always good to have the source. While very much not exhaustive, the page provides an interesting peek at the thinking behind an amazing technical achievement, emulating at least some games from a 3D-focused console during its lifespan, at a time when consumer 3D cards were relatively novel (the Voodoo2 was released the year before UltraHLE).
Some quotes:
There has been no attempt to translate the RSP code, since it works so closely with the hardware and uses integer arithmetic. Instead the C-code can use floating point, which is easier and faster on the PC. This means the results are not 100% same as those on the real console, but on the plus side things are a lot faster, and often results look better (for example increasing game resolution is trivial).
What helps us, is that the games don’t use the CPU to its full extent. Practically no 64-bit code is used, and virtual memory usage is limited.
On a Pentium II the R4300 emulation speed is now close enough to allow real time operation on many games and demos. Of course the PC has to do the work of the Reality Co-Processor too, so that will slow things down. But PCs are getting faster, and a 450Mhz Pentium II should run at excellent speed.
Expand for the full text!
UltraHLE Architecture
If you are interested in programming or emulators in general, this text is for you. The purpose is the explain the basic architecture behind UltraHLE and tell how it differs from many other emulators.
The HLE in the name pretty much sums it up. It stands for High Level Emulation. Instead of trying to emulate the hardware as closely as possible and supporting low level operations, the approach is just the opposite: Emulate as little as possible and try to detect operatios as early as possible, and emulate them using optimized C-code.
For example there is no boot rom and even boot code in rom images is ignored. Common operating system routines like interrupt adjustments are intercepted and ignored. When dealing with graphics and sound, the abstraction level is high (display lists and sound lists). CPU and DMA emulation is at a lower level, but still uses some tricks to detect common operations and perform them more efficiently.
This probably wouldn’t work on an older console, where low level programming and hand tuned assembly were the rule. But the Nintendo64 is quite different. Most of the code is written in high level C eliminating need for 100% exact CPU emulation (so things like exceptions or virtual memory can be emulated only approximately). Graphics and sound both use command lists, that are reasonably standard between different games.
Graphics and Sound
On the real console display and sound lists are executed using the Reality Signal Processor (RSP) which executes code from the rom image. It is a vector processor with operations specifically designed for fast geometry and audio, and as such is difficult to emulate efficiently. In UltraHLE the lists are interpreted with C-code, which has been created by studying the lists games generate. There has been no attempt to translate the RSP code, since it works so closely with the hardware and uses integer arithmetic. Instead the C-code can use floating point, which is easier and faster on the PC. This means the results are not 100% same as those on the real console, but on the plus side things are a lot faster, and often results look better (for example increasing game resolution is trivial).
It is also possible to do things the original code doesn’t do. For example, on the N64 loading new textures is a rather fast process, and all textures are loaded each frame. On the PC 3D-architectures, texture loading is generally a slower operation. The solution is to cache textures on the PC side and eliminate all unnecessary loads. This give a big performance boost and practically all textures can be cached, since PC has so much more texture memory.
Other display optimizations include removal of hidden triangles, extra matrix loads, unused mode changes and the like. Since texture and mode changes are more expensive on the PC, it makes sense to do extra geometry processing to eliminate as many changes as possible. Triangles are also collected into larger groups (sorted by mode) to allow faster rendering.
Finally, the graphics emulation has to cope with all the different rendering modes of the N64. The RCP contains a very configurable 3D-rendering unit which supports many modes that are impossible to emulate directly on 3DFX, even when using glide. UltraHLE performs pretty complex mode conversion to find the best PC-modes for each N64-mode. Things that the N64 does in a single pass are converted to 1-3 passes on the PC, depeneding on mode complexity. The modes are cached like textures, so the relatively slow mode decoding process does not slow things in practice.
Since there is so little information on Nintendo64 hardware, emulating sound and graphics on hardware level would probably have been extremely difficult (unless one had access to all N64 documentation, which we didn’t). So in a way this high level approach was pretty much the only way to proceed. But it was a good way nevertheless, as the results show.
CPU Emulation
The high level approach doesn’t extend that well to CPU emulation, but luckily the CPU is a standard MIPS R4300 with excellent documentation available. So it’s just a matter of following instructions, and then making it fast (which is the hard part). What helps us, is that the games don’t use the CPU to its full extent. Practically no 64-bit code is used, and virtual memory usage is limited.
Initially the CPU was emulated in C like in most emulators to get things started, but that was way too slow. The next logical step also was to compile MIPS code into Intel code. All instruction decoding overhead is eliminated, but it still takes multiple Intel instructions to emulate a MIPS instruction (since MIPS has more registers and because the Intel FPU implementation just plain sucks). Also things like branches are not that easy to handle. The speedup was about 5-10x compared to C-emulation.
The next step was to add optimizations to the compiler. By allocating MIPS registers temporarily into the few Intel registers, many memory accesses can be eliminated. This allows compiling small connected instruction groups into about 2 Intel ops for each MIPS ops ratio. Nearby memory accesses with similar addresses can be simplified by caching the base addresses in registers. It is also possible to replace some RISC instruction pairs with single CISC instructions. Since our target (Pentium II) does out of order execution, it was not necessary to reorder instructions, which made optimizations a lot easier. These optimizations increased speed 2x.
On a Pentium II the R4300 emulation speed is now close enough to allow real time operation on many games and demos. Of course the PC has to do the work of the Reality Co-Processor too, so that will slow things down. But PCs are getting faster, and a 450Mhz Pentium II should run at excellent speed. And there are probably more possible optimizations, just waiting to be done.
Compatibility
UltraHLE is a very unusual emulator. It doesn’t run many titles (yet), but what it runs, it runs well. This is because the high level emulation routines either work (if what they assume of the game is corrent) or they fail (if the game uses a totally different display list format, for example).
The goal of UltraHLE is not to run as many titles as possible. It is to run the best titles as well as possible. And looking at the current compatibility list, this is exactly what UltraHLE does. Compatibility will no doubt improve in the future, but the emphasis will still be on quality instead of quantity.
Omnivore Alternatives
Nov 4, 2024
It is with great prescience that I sadly relay news that Omnivore is going away:
We’re excited to share that Omnivore is joining forces with [some AI thing] […] All Omnivore users will be able to export their information from the service through November 15 2024, after which all information will be deleted.
So I’ve gone back to comparing self-hostable alternatives to avoid this happening again. My main criteria are:
- easily self-hostable
- a read-it-later service for articles, not just a bookmark manager
- Nice to have:
- highlights/annotations
- a mobile app for offline viewing and OS-level sharing of links
Here are the options I’ve found:
| Name | Highlights/annotations | Mobile app | Notes |
|---|---|---|---|
| Linkwarden | ❌ | ❌ | Demo instance. General UX is actually pretty nice. Seems to be primarily a bookmark management service. Does save archived snapshots of pages in various formats, but these are a little fiddly to navigate to - the default interaction is to just open the live link |
| wallabag | ✅ | ✅ | I was using wallabag for a while before moving to Omnivore. The feature set is perfect, but both the web interface and mobile app feel a little clunky and the Android context menu to annotate/highlight doesn’t behave consistently |
| Readeck | ✅ | ❌ | Despite not having a native mobile app, there’s a lot of great stuff here. The UX is clean and simple (quite similar to Omnivore’s), it’ll grab video transcripts where available, it can export to epub and there’s a browser extension (which works on Firefox Android) to send the contents of weird JavaScript festivals that it can’t scrape directly from the HTML alone. As a bonus, the dev knocked together an importer from Omnivore right after they announced they were shutting down |
Wallabag ticks all the boxes, but Readeck feels so much nicer to work with…it’s just not going to be with me on the tube. Between the browser plugin and some HTTP Shortcuts workflow, sharing to the service is covered. It’s really just the offline syncing I’m missing. I’ll be sticking with Readeck for a while, and ultimately if the lack of apps becomes a deal breaker, I’m sure I’ll be able to move everything to wallabag easily enough.
I’d really love someone to fork the open source Omnivore mobile apps and make them talk Readeck instead. Maybe if I can find some time…
2024-10-06 Sunday Links
Oct 6, 2024
- Getting my daily news from a dot matrix printer - Andrew Schmelyun via Ben Werdmuller - we had (old) printers like this in the home growing up and there would be something very nostalgic about reading a daily roundup on dot matrix paper
- DOOM ported to run almost entirely on AMD GPUs - GamingOnLinux - don’t waste your spare GPUs mining crypto or generating derivative artwork- play Doom instead! More importantly, today I learnt that LLVM can compile C++ to run on the GPU, via AMDGPU and NVPTX backends.
- Experiencing Old Games In New Eras - Brain Baking - thoughts on how even playing games on original hardware can’t recreate the original experience
even if you manage to grab a few other nerdy friends that cling onto their original hardware like I do. There’s nothing left to explore: everything is available on the internet; on GameFAQs, Wikis, fan pages, disassembly articles, generators
- Ruffle for Libretro - Jesse Makes Things - I stumbled upon a RetroArch/libretro core for Adobe/Macromedia Flash. I’d love to get this building for ARM handhelds. Maybe I shall try!
2024-09-29 Sunday Links
Sep 29, 2024
- Selling a small front-end web project — what I learned - Alistair Shepherd - a nice writeup on the process and experience of selling a small website, My Top for Spotify
- It’s Lists All the Way Down - The History of the Web - the wolrd wide web is lists
lists have been really foundational for the transmission of information. Writing in New York Mag, Kyle Chakra explores how Wikipedia, in some ways a logical extension of Otlet’s original idea for a a Universal Bibliography, has even gone as far as creating meta “lists of lists,” which help organize and rearrange the lists of information. There’s even a lists of lists of lists.
- Chris Shiflett: “There’s nothing quite like tight kerning to make a design look dean and modem.” - Mastodon - an 11/10 joke
- I implore you to do something useless - TonyD’s Substack - the importance of being idle
Creativity requires a mélange of experiences that cannot be quantifiable. They include but are not limited to: quiet contemplation, boredom, inspiration, taste, style, genre, motif, and dozens of others. These experiences do not come on-demand. They require a specific state of being that can only be acquired away from the measured and regimented processes that society loves too much.
- Ultima Online Classic Client Upgrade – Ultima Online, via Massively - UO played a huge part of my youth and it’s amazing to hear that the devs are working on with the ClassicUO folks to keep the classic client (or at least a classic client alive)
we are working with the developers of the third-party client “ClassicUO” with the goal of making available an officially sanctioned version for use on all shards
- Playing: I’m a few hours into Zelda: Echoes of Wisdom and it’s a lovely, chill time so far, with some vague Scribblenauts vibes.
- Reading: The Practice of Not Thinking - more importance of being idle
Jekyll Short URL Generator
Sep 25, 2024
I was reading this post by J about setting up a simple URL shortener with no server-side logic and it got me wondering if there was a Jekyll/GitHub Pages “native” way to implement something similar. It turned out to be very simple to put together!
redirect.html layout
Basically my regular layout with a couple of changes:
<script>
const url = new URL(window.location.href);
const stay = url.searchParams.get("stay") != null;
if (!stay) {
window.location = ""
}
</script>
<noscript>
<meta http-equiv="refresh" content="0; url=" />
</noscript>
Some simple JavaScript to redirect to the target page, unless a stay query parameter exists. If JS isn’t available it’ll use the meta tag to redirect.
_config.yml
Add a new scope
- scope:
path: ""
type: "redirects"
values:
layout: "redirect"
…so that redirect entries use the new layout
Add a new collection type
collections:
redirects:
output: true
permalink: /s/:name/index.html
…which will cause redirect pages to be generated at http://ste.vet/[redirectname]/index.html. This allows them to be accessible at http://ste.vet/[redirectname] with no special serverside logic or web server config to handle these paths.
Add the redirect entries
Now I’m able to add a [redirectname.md] to my a _redirects folder, and all they need to contain is:
---
redirect: [url]
---
So you can now hit http://ste.vet/s/mastodon to get to my Mastodon page, or http://ste.vet/s/mastodon?stay to hold on the redirect page! I didn’t have any particular usecase for this and it was more idle noodling, but J’s application of theirs for QR codes to stick on luggage pointing to a Lost & Found page is very smart!
2024-09-22 Sunday Links
Sep 22, 2024
- Cristiano Ronaldo Is In Fatal Fury: City Of The Wolves, For Some Reason - their title, not mine
- Anniversary: Tekken Is Now 30 Years Old - While that is indeed a very long time, the thing that caught my eye here was
Created by Seiichi Ishii, the original Tekken was released on 21st September 1994 on the System 11 arcade board, which was based on the PS1 hardware.
which I had not been aware of. Wikipedia corroborates
System 11 is based on a prototype of the PlayStation

- ‘New’ version of Half-Life discovered with cut content and secrets - a late beta test of Half-Life has been rediscovered, dated about a month before the final release
- Lost & Found stickers - Smart idea: Lost & Found QR code stickers for luggage etc
- hoarder-app/hoarder: A self-hostable bookmark-everything app (links, notes and images) with AI-based automatic tagging and full text search - a nice-looking self-hosted bookmark and snapshot archive app. Also a really great reference for other self-hosted alternatives
2024-09-15 Sunday Links
Sep 15, 2024
- How to Monetize a Blog - A literal satirical art piece on monetising blogs
- The Web of Alexandria (follow-up) (2015) - A thoughtful piece on why both the ephemerality and the preservation of the web are problematic
historically, people have relied on different media for different social purposes, and have relied on a clear understanding of how the technical properties of each medium determine the social and temporal scope of its messages. Think about speech, letters, newspapers, books, smoke signals… Each medium serves only a particular subset of social purposes, and each medium is technically transparent enough that people can understand what’s happening when they use it.
- PySkyWiFi: completely free, unbelievably stupid wi-fi on long-haul flights - My new favourite dumb computer project: a system to proxy the web through fields in an airmiles profile to allow free, unrestricted browsing in the sky
Feediverse
Mar 15, 2024
What if we had a great experience that ties together both short-form discussion and re-sharing and long-form reading, in a way that better showcases both kinds of content and realizes that the way we consume both is different? What if it had a beautiful, commercial-level design? And what if it remained tied to the open social web at its core, and pushed the capabilities of the protocols forward as it released new features and discovered new user needs?
Copy and paste from Obsidian with formatting
Oct 21, 2023
tl;dr: Copy as HTML plugin
Copy/pasting from Obsidian has some issues. The first problem I hit was that pasting into Slack was coming through as unformatted text - the raw Markdown. After a bit of fiddling, switching from Edit to Reading mode resolved this. Pasting from Reading mode properly formats the text.
Pasting into Google Docs created some more interesting problems though. While Reading mode carried the formatting through, it also brought elements of my Obsidian theme, like background colour which, naturally, wasn’t what I was looking for. Then I found the Copy as HTML plugin, which handles its own Markdown to HTML conversion and copies the output from that, avoiding bringing along any unintended elements from the editor. This leads to a nice workflow where you can draft and edit documents in Obsidian, keeping them close to other notes to allow for future remixing/cross-referencing etc, while making it easy to transfer it to Google docs to share or collaborate on.
Omnivore, the free, open source read later app
Oct 12, 2023

I’ve been using Wallabag as a self-hosted read later service for a while. Like a free, open source Pocket/Instapaper. It works well enough, but the general UX is a little rough around the edges and development doesn’t seem super speedy - the Android app hasn’t seen a release in a couple of years. I recently stumbled upon Omnivore and it’s already won me over.
The good
- The look and feel is generally very pleasing - it has a similar feel to Pocket
- You can use all the functionality on the hosted instance at omnivore.app for free
- You can customise your reading experience, from the font face right down to the margin size
- There’s a beta RSS reader. I already use FreshRSS so this isn’t super valuable to me personally - I’m happy to manually “promote” content from RSS to read later - but if you’re only working with a few feeds with high quality content, I can see this being handy
- Email inboxes. You can setup email addresses to register with newsletters and have them come straight through to Omnivore. You can also send PDFs and highlight/annotate as with articles
- Regular updates. The Android app was updated last week
- Offline reading in the apps
- Highlights export through well-maintained plugins (Obsidian & Logseq) straight into your notes. Wallabag highlights/annotations use XPath notation, which I’ve found difficult to write markdown export scripts maintaining full formatting from the original article
- It’s self-hostable…ish ⬇️
The less good
- I gave up on self-hosting
- Hosting under a domain name didn’t “just work” - even after setting all the URLs in the
docker-composefile, I was still directed to alocalhostURL - I did a find and replace to change all
localhostreferences to my instance’s URL but wasn’t able to add content - The team are actively working on making it “more self-hostable” so I’ll try again some time!
- Hosting under a domain name didn’t “just work” - even after setting all the URLs in the
I’m finding it very enjoyable to use and I think I’m a convert! As I’m not currently self-hosting there is every chance the hosted service may go away or my data get lost, but I’ll keep exporting my highlights and spin up my own instance once they’ve ironed some of the kinks out!
Arc Browser And Tim Berners-Lee's Dream of Intercreativity
Jul 29, 2023
As I was reading Tim Berners-Lee’s book on the origins of the web it became clear that TBL has, or had, a real passion for democratising the creation of the web and for people to be able to create content directly in the browser, even editing the content they’re viewing.
We ought to be able not only to find any kind of document on the Web, but also to create any kind of document, easily. We should be able not only to follow links, but to create them - between all sorts of media. We should be able not only to interact with other people, but to create with other people. If interactivity is not just sitting there passively in front of a display screen, then intercreativity is not just sitting there in front of something ‘interactive’.
Throughout the book TBL seems frustrated that his idea that a web browser should also be a web editor never took off:
A long-standing goal of mine had been to find an intuitive browser that also, like my WorldWideWeb, allows editing. A few such browsers/editors had been made, such as AOLpress, but none were currently supported as commercial products. Few items on the wish list for collaboration tools had been achieved. At the consortium we wondered what was wrong. Did people not want these tools? Were developers unable to visalise them? Why had years of preaching and spec writing and encouragement got hardly anywhere? p183
The W3C even developed the Amaya browser/editor, which is able to create and edit content in place - the Github repo was archived in 2018.
I saw that the Arc browser came out of invite-only testing on Tuesday and looked around at the feature set.
- With Easels, you can create whiteboards/moodboards/dashboards with clippings or live views from the web and share them
- Boosts allow you to restyle and “edit” (override, for you) content on the web
- You can take Notes directly in the browser and share them
I doubt any of this is exactly what TBL had in mind in the 90s, but this idea of being in control of the web and generating and sharing content directly in the browser definitely feels like it fits into his philosophy.
Hostname Aliases on a LAN In Linux
Jul 27, 2023
I have a little computer running Linux in my home that I use a home server, running various services such as FreshRSS and linkding. I wanted to setup a bunch of memorable hostnames I could use to point to different services on that machine. This was my journey.
My primary OS is Windows. I’m used to using the machine name (hostname) of the computer to resolve to its local IP address by some sort of magic with no human intervention (apparently this is NetBIOS? I dunno, I’ve literally never had to think about it), but that wasn’t working for this Linux server PC. After trawling through a bunch of StackExchange posts suggesting the user edit their hosts file…on each and every device on their LAN, which is obviously the wrong way around, I found posts such as this helpfully indicating that the functionality is offered in zero-conf(iguration) services, such as mDNS and that installing Avahi on the Linux machine should broadcast the hostname as hostname.local and then be available by name rather than just IP. After a quick
sudo apt install avahi-daemon
this all worked pretty promptly!
I then got to thinking “wouldn’t it be neat if different web services, running on different ports, could be referred to directly by a name?”. After some more frantic Googling I found this amazing post from Andrew Dupont walking through basically my exact usecase. The Python mdns-publisher seemed perfect for what I needed, but unfortunately it bound to the wrong network interface/IP address and as far as I can see there’s no parameter to change that. I ended up using something inspired by Andrew’s clearly less-perfect solution but it totally did the job, basically boiling down to a bunch of calls to
avahi-publish -a freshrss.local -R 192.168.1.100 &
avahi-publish -a linkding.local -R 192.168.1.100
(etc).
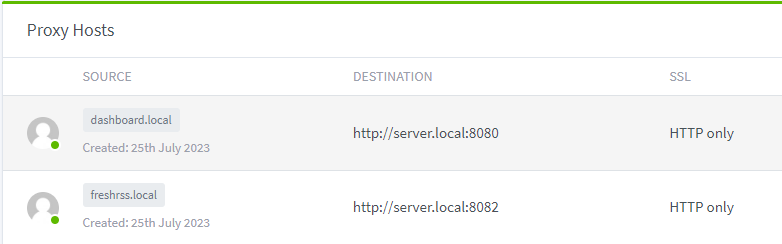
All hostnames were now mapping to the server’s IP address correctly, but the port still needed to be specified - this was effectively basic aliases for an IP. The next step in Andrew’s article is to setup nginx proxies. Having seen nginx config syntax before, I didn’t really fancy that so looked around for more accessible solutions. I eventually stumbled on Nginx Proxy Manager. I threw together a docker-composse.yml based on their example and the UI was super-legible and looked easy to configure. After making some entries to map the Avahi mDNS names to http://hostname.local:[port] everything was working!
Weaving The Web, by Tim Berners-Lee
Jul 13, 2023

Weaving The Web - The Past, Present and Future of the World Wide Web by its Inventor by Tim Berners-Lee, 1990
A couple of years ago I went on a quest to find the perfect note-taking software for me. I dabbled with Roam, but was looking for something less siloed. I tried TiddlyWiki, but found the tech stack quite clunky, as straight out the box it’s just an HTML file that has no way to write your changes anywhere. Eventually I stumbled on Obsidian, which was exactly what I needed: local notes, Wiki-style interconnected-ness with simple and (relatively) standardised Markdown for formatting. It got me thinking about the structure of the web and how fundamental links and connections should be. I was inspired to read Tim Berners-Lee’s book on the origins of the web. I took a bunch of notes, but these are the ones that resonated most strongly.
I’ll refer to Tim Berners-Lee as TBL to save us all some characters.
From the foreword by Michael L. Dertouzos, then-director of MIT Laboratory for Computer Science.
When I first met Tim, I was surprised by another unique trait of his. As technologists and entrepreneurs were launching or merging companies to exploit the Web, they seemed fixated on one question: ‘How can I make the Web mine?’ Meanwhile, Tim was asking, ‘How can I make the Web yours?’
Origins
- The seed of the idea that computers could become a web of connected information was planted while TBL was in high school, after a chance conversation with his dad about the potential for computers to be more intuitive if they were able to model connections as the brain does.
- TBL envisaged a generic addressing scheme which would allow arbitrary connections, where previous hierarchical/folder/directory structures led to very rigid, restrictive, mutually exclusive relationships.
- 1965 - The concept of hypertext was established long before Tim’s first forays with it, with Ted Nelson writing about it in Literary Machines
- Nelson also coined the term intertwingularity to represent the idea that concepts don’t fit cleanly into boxes and ultimately everything is interconnected, which sums up a lot of what TBL was thinking about. His original work can be found in a sample chapter of The New Media Reader book.
Early iterations
Enquire
- 1980 - TBL’s first attempt at software to represent an information web, Enquire, was developed purely for his own use a full decade before his first client/server Web. He was already thinking about a platform that supported arbitrary conceptual linkage, as well as connections between computers.
- It required a description of the connection between linked documents. This imposes database-style relationships between concepts, where semantics can then be reasoned with and queried but would feel artificial in longer-form prose.
- Links were bi-directional - a concept that can only really work in a closed system, where one owner controls all the documents.
- I’ve just discovered that the original Enquire manual from 1980 is hosted by W3C.
Tangle
- Late 1984 - TBL took another shot at developing software for connecting ideas called Tangle.
- As with Enquire’s well-defined connections, Tangle was another example of TBL’s fascination with the semantic web, where meaning can be derived systematically. His intention was that you could build layered definitions/compositions of, and connections between, concepts to the point that the computer could break a question down into concepts it knew about to pull out strands of associated information.
R&D and beyond
- March 1989 - TBH developed a pitch for his idea for an interconnected documentation solution, to keep track of connections between people, their work and work artifacts
Now imagine picking up the structure and shaking it, until you make some sense of the tangle: perhaps you see tightly knit - groups in some places, and in some places weak areas of communication spanned by only a few people. Perhaps a linked information system will allow us to see the real structure of the organisation in which we work.
- September 1990 - Hypertext was already a big enough deal that he was able to track down the European Conference on Hypertext Technology, held at Versailles, to pitch his idea
- Looks like there were only 3 held, each 4 years apart, with 1990 being the first.
- He tried to convince Electronic Book Technologies, developers of Dynatext, to convert their “electronic book” software into a web browser/editor as the changes required seemed minimal. He was met with a lot of resistance as traditional media companies were stuck in their traditional media-ways, needing central databases and never allowing broken links; where a publication stands complete by itself.
The WorldWideWeb in production
- Christmas 1990 - The end-to-end proof of concept, with a server handling connections from at least two clients over the internet using TBL’s WorldWideWeb browser (/editor hybrid).
- August 1991 - TBL went public on newsgroups, posting his NeXT-compatible browser, a line-mode browser and a basic web server.
- He also made the smart move of allowing telnet connections to a server running the line mode browser, to allow the internet at large to dabble with the web using only their existing software/setup.
- December 1991 - The first web server outside of CERN was launched at the Stanford Linear Accelerator in Palo Alto.
- May 1992 - Over-the-air code a la scripts/applets was demonstrated in in Pei-Yuan Wei’s ViolaWWW.
- TBL wanted the document reference address to be called a URI, as identifier suggested immutability. The IETF work group pushed for URL, as Locator suggested the same document could move. Tim eventually went on to channel his philosophy in Cool URIs don’t change in 1998.
- 1993 - Mosaic was released for free to remove any barrier to entry and proliferate instantly.
They also seemed to follow the unprecedented financial policy of not having a business plan at first: they decided not to bother to figure out what the plan would be until the product was world-famous
- 1994 - Microsoft bought in the browser code of a small NCSA spin-off named Spyglass to kickstart the project that would become Internet Explorer for $2 million (around $4 million 2023 dollars)
- TBL notes that by Netscape being early to market and giving their browser away for free, bringing millions of people to their home page and giving ad impressions, and then charging for commercial licences and web services, they were “acknowledging that on the Web, it was more profitable to be a service company than a software company”. This seems like a profound observation for 1999 (or earlier).
- May 1995 - Sun announced the HotJava browser with integrated Java VM, as well Netscape announcing Java support. TBL notes that Java was a “repackaging of James Gosling’s Oak language, originally designed for applications such as phones, toasters and wristwatches.”.
- I can’t find a citation for those devices specifically but plenty around set-top boxes and PDAs. Regardless, A Brief History of the Green Project states that they “quickly came to the conclusion that at least one of the waves was going to be the convergence of digitally controlled consumer devices and computers”. This would all, of course, come full circle when phones, wristwatches, and probably toasters run Android.
The Future
- TBL sets out his vision
- The web becomes more of a platform for collaboration.
- I think we’re broadly here with a lot of large web sites having some element of user generated content. However, the majority of content users are generating isn’t adding to the “web” so much as adding content to a given platform. This distinction is basically what the indieweb is all about.
- “Machines become capable of analysing all the data on the Web”, followed by an explicit reference to semantic web.
- It’s arguable we’ve achieved this after going around all the houses. Large language model neural networks give us a similar, if fuzzier, end result while still allowing for content to be written in plain written language, without additional markup or metadata overhead.
- The web becomes more of a platform for collaboration.
- To achieve his vision, TBL says we’ll need:
- a computer (screen) always available
- Think we can tick this off with the ubiquity of mobile devices/laptops/personal computers.
- permanent/instant internet access
- This too, through broadband and mobile internet.
- a computer (screen) always available
Some observations
- TBL was really hooked on the idea of hybrid web editors and browsers; of making the web “intercreative”. I can see the power in this, but I guess the technical logistics get a little weird. Serving HTML is very different from building a form to receive and store data to then inject into that HTML.
- He was also really taken by Semantic Web. The concept pops up in a lot of forms throughout the book and it seems that it’s only been realised on a very superficial level. It feels that with the rise of LLM / “AI” we’ve reduced the need for the web to be machine-parsable at a structural level, and we can, broadly speaking, reason with raw text. We’ve ended up solving it from the other end, accepting that the web is just context-free noise-soup, and relying on algorithms to derive patterns from it.
- There’s no mention of JavaScript, which seems surprising for a book published in 1999. It was definitely an accepted and used language, but maybe not used in any capacity significant enough to warrant mention?
I was reading the book out of an interest in the origins of the web and the tech that drives it. I didn’t take notes around the formation and operation of the W3C, or some of the loftier crystal ball-gazing as it wasn’t relevant to my specific context. This was a nice quote though (emphasis mine)
Bias on the Web can be insidious and far-reaching. It can break the independence that exists among our suppliers of hardware, software, opinion and information, corrupting our society.
Gemini Why And How
Jan 21, 2022
I thought I’d start off by explaining why and how I setup a Gemini server.
Why
We were chatting at work about the issues with the modern web - speed, cruft and general usability. Someone dropped a link to the Gemini project page.
It resonated with me, particularly because it doesn’t expect to be, and isn’t trying to be, a replacement to the web, but an alternative with a focus on signal-to-noise ratio. The markup for formatting text, gemtext, is Markdown-like and minimal, both in terms of characters/bytes used and range of functionality. There are 3 levels of (sub-)headings, links, blockquotes and pre-formatted text. And that’s it. It’s all making room for that textual content. I thought it’d be a fun project to setup my own Gemini server, ideally for as close to free as possible.
How
After a little research I settled on gmnisrv as the server program- I found a bunch of people using it and it doesn’t have a ton of dependencies.
I’ve wanted to learn Docker for a while, so I spent enough time researching it to cobble together something that would build gmnisrv and host a placeholder page locally
Then I had to figure out where to host it. There are many, many free-or-almost-free options for hosting something running over http/https but a lot fewer with the flexibility to serve stuff on not-port-80-or-443. However, I found that Google Cloud Compute’s free tier offers a low-end VM that should be more than capable to serve any throughput I’ll get on this page. Specifically they offer:
- 1 e2-micro VM in a handful of US regions
- 30GB standard persistent disk
I spun up an instance, setup SSH keys, SCPd over my Dockerfile, setup port forwarding and got gmnisrv running. I opened Gemini client Lagrange and pointed it at the VM’s IP address and was served my page!
I then wrote a (very) small Python script to run over all the gemtext files in a folder (e.g. blog posts) and build an index page. All the metadata is encoded into the filename- this is 2022-01-21-why-and-how.gmi, which will go on to generate the date and title/heading for the post. As the markup is so similar to Markdown, I thought I’d also generate a Markdown representation to mirror the posts over in my Github pages page, which is, let’s be honest, where you’re probably reading this.
I’m hoping to use this as a place to form a habit of writing posts to synthesise and clarify my thoughts on topics I’m reading and thinking about. Let’s see!
Debugging Unity Android Apps
Jul 23, 2018
This is pretty much a repost/summary of a StackOverflow post, as it took me a long while to find this information; hopefully Google will do its magic and surface this for future generations.
I had a need to debug a Unity game on an Android device. The build running on the device was a Development build with debugging enabled etc etc. For reasons I had neither time nor inclination to investigate, Visual Studio was not discovering the device and it was not showing in the Attach Unity Debugger list, despite the device being on the same Wifi network, and physically attached by USB cable. I knew the IP address of the device, but not the port the debugger process was listening on, which apparently changes with each launch.
To summarise the StackOverflow post, you want to get hold of the ADB logcat output for your game. I did (something like):
adb logcat -c
adb logcat > out.txt
(launch game on device)
(wait some period of time)
(CTRL + C)
…which will dump the logcat output to a file called out.txt . If you now search for monoOptions in the file you should see a line like:
Using monoOptions --debugger-agent=transport=dt_socket,embedding=1,defer=y,address=0.0.0.0:56785
If you add the device’s IP address with the port from above to the Visual Studio Attach Unity Debugger window, it should now connect, obey breakpoints and the like!
How and Why Is This Object Being Destroyed, Unity?!
Jul 17, 2017
I recently ran up against a problem in a Unity project I’m working on: a GameObject was being Destroyed, but I didn’t know why or from where. The codebase, naturally, has many calls to Destroy() and contains its own methods with that name, which made both Find References and text-based searches impractical. I just wanted a breakpoint in UnityEngine.Object.Destroy().
Round 1: OnDestroy()
Spoilers: you may well know this method is a dead-end.
Unity will automatically call OnDestroy() on all components on a destroyed GameObject. I thought this might allow me to set a breakpoint, but OnDestroy() is deferred to the end of the frame, so the callstack doesn’t go back to the original Destroy() call. Next!
Round 2: Hacking Unity’s IL
A discussion with a friend led to the idea of modifying the .NET IL in Unity’s DLLs to modify the contents of UnityEngine.Object.Destroy(). I Googled upon Simple Assembly Explorer, which allows you to view and modify the IL of compiled .NET binaries. Without any prior knowledge of .NET IL I was quickly able to insert a ldarg.0, to push this onto the stack as the argument for the next function call, and a call instruction, to call out to UnityEngine.Debug.LogWarning, which would give me a stack trace.
I booted up my project in Unity and sure enough, every call to Destroy produced the log I hacked in there. Amazing!
While this worked, it felt very fragile: any future update to Unity would stamp over this, and I didn’t fancy learning IL to build this out further.
Round 3: Harmony
I was aware of the concept of hooking/detours from lower level, C++/assembly code, and was interested whether something similar existed for .NET/C#/Mono/Unity. Google led me to Harmony on GitHub:
A library for patching, replacing and decorating .NET and Mono methods during runtime.
Not only does it support Unity, it’s built with Unity in mind- the example code is a mod for a Unity game. I was able to copy and paste the example code into a fresh project referencing the Harmony DLL, change the target class to UnityEngine.Object, the target method to Destroy and the target parameter to a UnityEngine.Object, then change the hooked method implementation to a log call. After a build, all I needed to do was drop my new DLL, along with the provided Harmony DLL, into the Unity project call the setup function to initialise the hooks and boom: the log was again produced on every Destroy. This has a bunch of benefits over the previous method, such as writing the patch in the language I was already using, not having to screw with binary file (so the patch’s code could happily live in source control), and being forwards compatible (unless Unity make any breaking API changes). In theory any C# Unity could be hooked in this fashion, which could be great for mocking functions or gaining a bit more control over what’s going on under the hood!
Sanitarium HD Patcher On GitHub
Dec 9, 2015
Just a quick update: I’ve open sourced my Sanitarium HD Patcher. The code and latest release can now be found on GitHub! Enjoy!
Sanitarium HD Patcher
Feb 7, 2015
It is now available! Please find v0.1.0 here. This version will only work with executables with MD5 of 0A09F1956FCA274172B0BB90AA5F08A7. If people turn out to have other versions I’ll try to get hold of the exes and get them supported. Enjoy!
UPDATE: Permanent page at sanitariumhd.
New Year's Resolution Patch
Feb 1, 2015
I guess that title would have worked better a month ago.
Anyhow. I’ve always been fascinated by software reverse engineering and general binary hackery, but had never really thought of a project to try it out on. Then I remembered the Fallout High Resolution Patch and the Infinity Engine Widescreen Mod, which apply cracking/patching techniques to allow old games designed at 1990s resolutions to run at glorious 1080p. I decided to do something similar.
Targeting
I wanted a target for which no fan patch already existed. I was browsing GOG, and saw that the game Sanitarium had recently been added. I remembered that I already had a copy installed on my PC - perfect! Target acquired.
Hacking Commences
The first step was to figure out what resolution the game runs at out of the box. To do this, I took a screenshot of the game running windowed (command line param -w, if you’re interested), and highlighted the rectangle excluding the standard windows border stuff. I’m sure there are more scientific ways to tell the size of a window, but this worked for me.
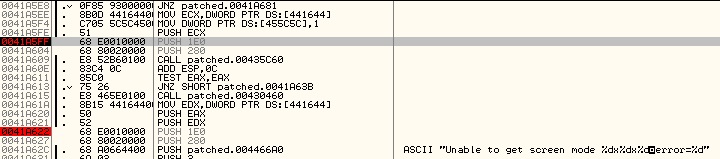
I deduced the game to be rendering at a 90s-classic 640x480. I opened up game in the trusty debugger, OllyDBG, and began investigating the heck out of it.
I searched for the number constant 480, set a breakpoint on each reference and ran the game. One of these was hit very early on in the initialization, and was proceded by a reference to 640 - strong candidate! (ignore the fact that the offsets are from patched - I’d already backed up the original executable)
I used Olly to patch the 640/480 values to 1280/720 respectively, and ran the game. The window was now 720p, with the main menu occupying the upper-left corner, but once in game it was rendering a much larger visible area. See below for comparison
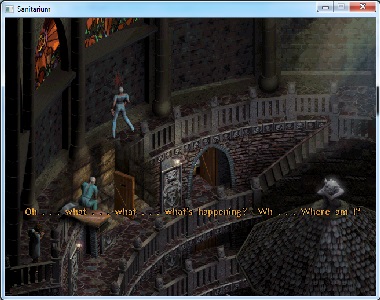
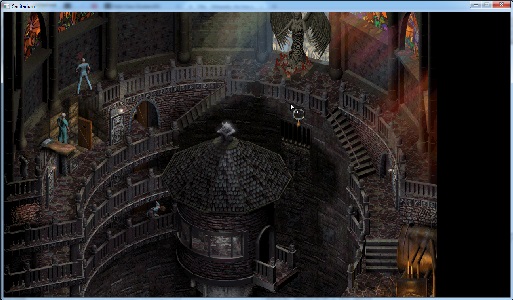
If you’re familiar with the game you’ll notice that all the game objects outside of the 640x480 camera the game is expecting aren’t drawn. I’ll address this later, but at this point I got ambitious(/distracted). The changes made in Olly can be saved out as a modified .exe, which can be used in the future. This would technically let me distribute the patched executable, allowing the wider internet to play the game at high-res. However, there are a couple of drawbacks:
- It’s pretty illegal: the modified version would still contain all the original code generated by the copyright holder
- It’s pretty inflexible: everyone using my modified executable would be stuck with the resolution I chose. Also if further changes were required a new modified executable would have to be obtained Solution: patch the executable in memory right before running it, just as Olly does.
Rolling a debugger
A quick bit of googling showed me that in order to modify executable code on the fly in Windows you basically have to write a debugger. This sounded very intimidating. I continued my research and it turned out to be conceptually very simple. All that’s required is a C++ project to do the following:
- Make a call to
CreateProcess, passing theDEBUG_PROCESSflag. This starts a child process owned by your executable, which sends debugger-relevant events to your code. - While you’re interested in these debugger events, call
WaitForDebugEvent/ContinueDebugEvent. The only event I needed wasCREATE_PROCESS_DEBUG_EVENT, so I handled that in a (very small) switch statement. When this event arrives I make a callDebugSetProcessKillOnExit, passing infalse, so after my patch is applied my program can close, leaving the game process to live on. I then… - …apply the patches. This is the part I assumed would be complex, but boils down to one Win32 API call.
The target’s executable code is memory mapped to an offset from a base address. For 32 bit Windows programs, this address is 0x00400000. I referred to the patches I made in Olly to get the address which needed to be modified. As can be seen in the screenshot of the debugger, we started with a PUSH 1E0, followed by a PUSH 280 (480 and 640 in hexadecimal). The compiled x86 machine code for PUSH [some 4 byte value] is 68 [some 4 byte value in little-endian] - 68 E001000 in our exaple. In this case, and most cases we’ll need to deal with, we can leave the PUSH (68) part untouched, and only change the operand (E001000). The program I wrote takes the desired resolution (x and y) as command line arguments and parses them as an unsigned 16 bit integer. We can then take a pointer to one of these values, cast it to a pointer to a byte, and treat it as a little-endian 2-byte array, like so:
uint16_t resY = parseInt(resYString);
uint8_t* resYBytes = (uint8_t*)&resY;The PUSH 1E0 happens at 0x0041A5FF. We can leave the first byte as 68 for PUSH, and just modify the 2 bytes at 0x0041A600/0x0041A601, to the 2 bytes of resYBytes. To do this we can use WriteProcessMemory, passing the offset we found with Olly as the lpBaseAddress param, the 2 byte array representing the dimension (e.g. resYBytes) as lpBuffer, and then the size to write as 2. That’s basically all there is to it. Once the patch for setting resolution width and height are applied, my program closes and lets the game carry on as normal.
Culling me softly
As I mentioned earlier, even with the resolution patches applied there are still some objects inside the newly-embiggened viewport which are not being drawn. Jumping back into Olly, I continued searching for 640/480. This lead me to the area of code below:
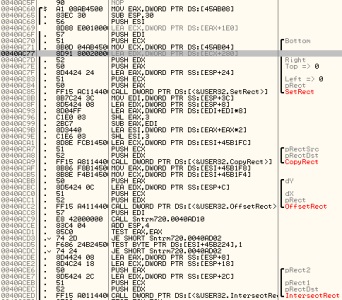
To ease both rendering and logic load, games often skip (or cull) objects which aren’t visible. I could see some calls to functions operating on Rects (IntersectRect/OffsetRect), and figured this could be the logic for culling offscreen objects, still using the hardcoded 640x480. Applying a couple more patches to bring these up to 720p I was presented with this:
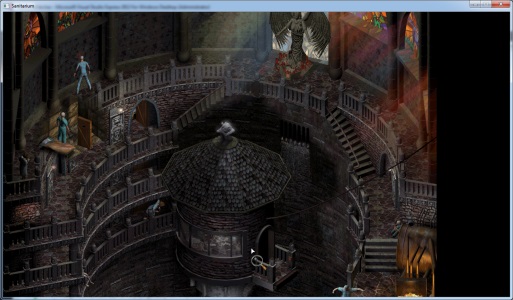
Note the extra dudes in the bottom right. Amazing! I then jumped over to my project and made the code a bit more generic, using a std::map<uint32_t, const uint8_t*> to store arrays of bytes to be patched in, indexed by their memory address. And that’s where I’m at. There is still one pretty glaring issue:
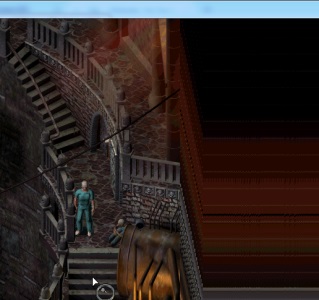
Previously the camera was restricted so it would never draw beyond the edge of the level. Now we’re drawing a bigger area around the player, empty space is visible. It looks like the surface the game draws to isn’t cleared every frame, leaving the remnants of the previous frame hanging around. I’ll need to figure out a way to clear it before the background is drawn to it, then we should be all set!
I also still need to add some validation of command line arguments, and I’ll make a follow up post with it (and hopefully the full source code) attached once it’s ready.